
Czerwiec 2026 | Kunya
W AI istnieje pojęcie, o którym większość ludzi nigdy nie słyszała. A jednak to właśnie ono po cichu decyduje o tym, czy AI udzieli Ci użytecznej odpowiedzi, czy kompletnie nietrafionej. Nazywa się context window — i gdy raz zrozumiesz, jak działa, już nigdy nie będziesz patrzeć na AI tak samo.
Zacznijmy od czegoś, co już dobrze znasz.
Twój mózg działa na najbardziej imponującym silniku kontekstu, jaki kiedykolwiek powstał
W tej chwili, nawet się nad tym nie zastanawiając, nosisz w sobie ogromną ilość kontekstu.
Wiesz, dlaczego otworzyłeś ten artykuł. Wiesz, czego szukałeś, zanim na niego trafiłeś. Wiesz, co wydarzyło się dziś rano w pracy, jakie masz relacje z szefem, jakie cele stawiasz sobie na ten rok. Pamiętasz rozmowę sprzed trzech tygodni, która subtelnie zmieniła sposób, w jaki myślisz o pewnym problemie. Nosisz w sobie emocjonalny kontekst całego dnia. Wiesz, do czego odnosi się „ta rzecz, o której rozmawialiśmy”, nawet jeśli nikt tego nie doprecyzuje.
To wszystko jest kontekstem. I utrzymujesz go bez najmniejszego wysiłku. Twój mózg w czasie rzeczywistym splata dziesięciolecia wspomnień, preferencji, emocji i wiedzy o świecie — i wykorzystuje to wszystko, by zrozumieć nawet najprostsze zdanie.
Kiedy partner lub partnerka pisze Ci „kupisz po drodze to co zwykle?”, dokładnie wiesz, co to znaczy. Do tej wiadomości nie jest dołączona żadna dodatkowa informacja. Kontekst masz w głowie.
AI tak nie działa. Przynajmniej jeszcze nie.
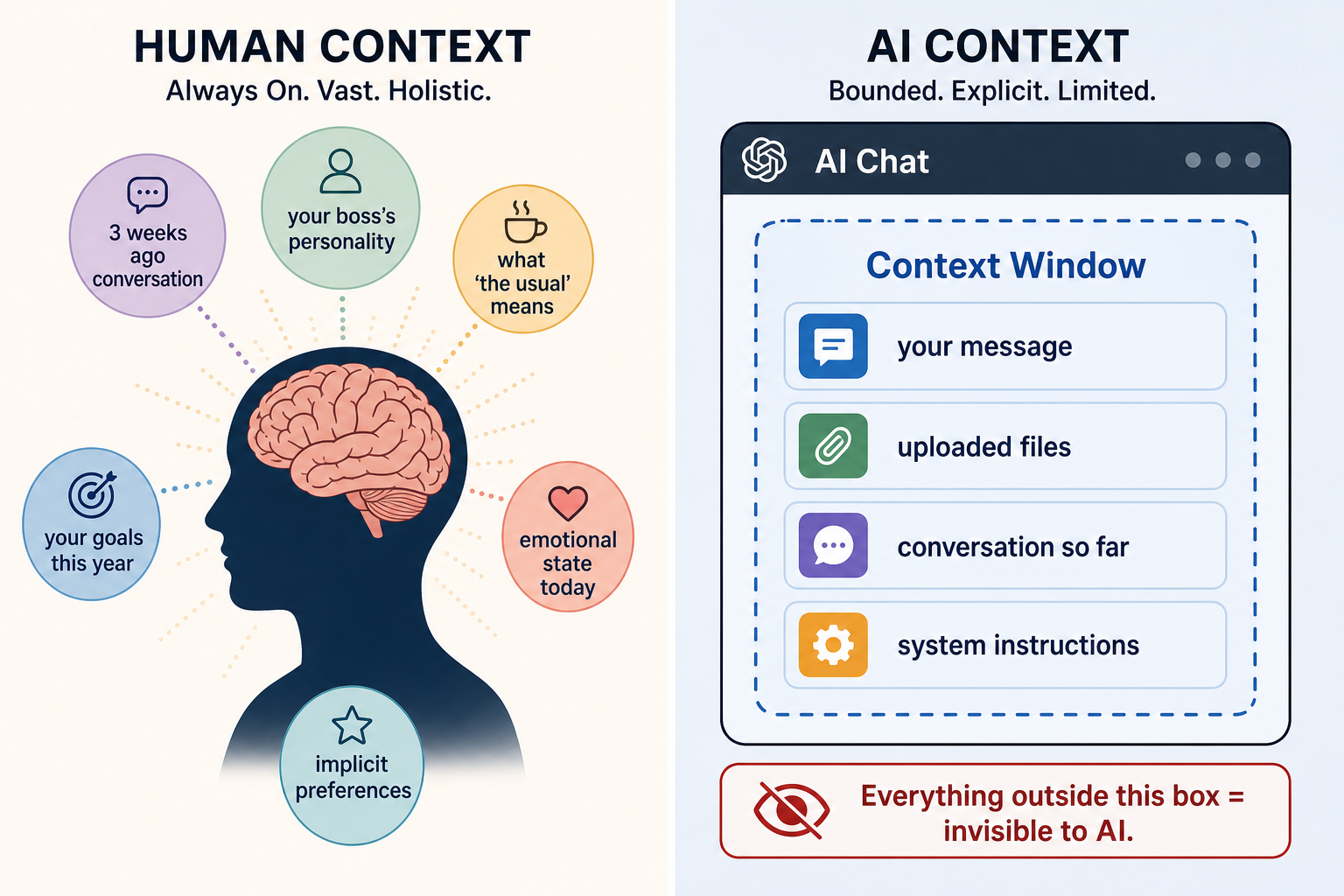
Twój mózg działa na silniku kontekstu, któremu żadne AI jeszcze nie dorównało — łącząc w czasie rzeczywistym dekady wspomnień, emocji i wiedzy.
Czym właściwie jest context window?
Context window to ilość informacji, którą AI może jednocześnie utrzymać i brać pod uwagę.
Za każdym razem, gdy otwierasz czat z modelem AI, zaczyna on od zera. Nie pamięta rozmowy, którą prowadziłeś z nim wczoraj. Nie zna Twojego imienia, jeśli mu go nie podasz. Nie ma żadnej wiedzy o Tobie, Twojej firmie ani Twoich celach. Jedyną rzeczą, którą „wie”, jest to, co aktualnie znajduje się w jego context window: Twoja wiadomość, przesłane pliki, otrzymane instrukcje oraz dotychczasowa historia rozmowy.
Kiedy to okno się zapełnia, niektóre rzeczy zaczynają z niego wypadać. Model albo streszcza wcześniejsze treści, albo pomija starsze fragmenty rozmowy, albo po prostu gubi informacje, które mu wcześniej podałeś.
Pomyśl o tym jak o pracy z genialnym współpracownikiem, który nie ma pamięci długoterminowej. Na każdym spotkaniu musisz przedstawiać się od nowa, tłumaczyć projekt od początku i powtarzać cały potrzebny kontekst. To nie tak, że nie jest inteligentny. Po prostu nie pamięta.
Tokeny: jednostka kontekstu
Context window mierzy się w tokenach, a nie w słowach czy znakach.
Jeden token to mniej więcej 3–4 znaki tekstu. Słowo „kontekst” to około dwa tokeny. Jedna pełna strona tekstu to mniej więcej 500–700 tokenów. Przeciętna powieść ma około 100 000 tokenów.
Oto orientacyjny przelicznik z życia wzięty:
Tokeny | Jak to wygląda w praktyce |
|---|---|
4,000 | Kilka stron tekstu |
32,000 | Krótka nowela |
128,000 | Pełnowymiarowa książka non-fiction |
200,000 | Około 500 stron dokumentów |
1,000,000 | Cała baza kodu, akta sprawy sądowej, 40 000 linii kodu |
To ma znaczenie, bo kiedy wysyłasz wiadomość do AI, do limitu wlicza się cała historia rozmowy. Twoja wiadomość, wcześniejsze odpowiedzi AI, wszelkie wklejone dokumenty — wszystko to zużywa kontekst. Gdy dojdziesz do limitu, coś musi ustąpić.

Context window to pamięć robocza AI — wszystko, co model widzi w tej chwili. Gdy się zapełnia, wcześniejsze treści zaczynają wypadać.
Dlaczego kontekst jest wszystkim
Oto szczera prawda: kontekst to cała gra.
Surowa inteligencja modelu AI ma mniejsze znaczenie, niż Ci się wydaje, jeśli nie ma on właściwych informacji do pracy. Możesz zadać najlepszemu modelowi AI na świecie pytanie bez żadnego kontekstu i dostać ogólnikową, przeciętną odpowiedź. Ale jeśli dasz nieco prostszemu modelowi pełny kontekst — swoje cele, grupę odbiorców, pożądany ton, tło sytuacji — możesz otrzymać coś naprawdę użytecznego.
Pomyśl o różnicy między proszeniem obcej osoby o radę a pytaniem bliskiego przyjaciela. Obca osoba może być nawet mądrzejsza. Ale przyjaciel zna Ciebie. Zna Twoją historię, ograniczenia i gust. Jego rada trafia inaczej, bo jest osadzona w kontekście.
Dokładnie tak samo działa to w AI. Jakość odpowiedzi niemal zawsze zależy od jakości i kompletności dostarczonego kontekstu — a nie tylko od tego, jak potężny jest sam model.
To także dlatego ludzie frustrują się AI. Zadają nieprecyzyjne pytanie, dostają nieprecyzyjną odpowiedź i uznają, że narzędzie nie jest zbyt przydatne. W rzeczywistości doświadczają po prostu problemu z kontekstem.
Wyścig o context window w 2026 roku
Branża AI doskonale wie, jak ważny jest kontekst. Dlatego ostatnie dwa lata upłynęły pod znakiem cichego wyścigu zbrojeń o maksymalne rozszerzanie context window.
Tak wygląda sytuacja w połowie 2026 roku:
Model | Context window |
|---|---|
Llama 4 Scout | 10,000,000 tokenów |
Gemini 3.1 Pro | 2,000,000 tokenów |
GPT-5.5 | 1,000,000 tokenów |
Claude Opus 4.8 | 1,000,000 tokenów |
DeepSeek V4 Pro | 1,000,000 tokenów |
Grok 4.3 | 1,000,000 tokenów |
Claude Sonnet 4.6 | 1,000,000 tokenów |
Dla zobrazowania skali: 1 milion tokenów wystarczy, by w jednej sesji pomieścić całą bazę kodu, miesiąc rozmów z działem obsługi klienta albo kompletne akta sprawy prawnej.
Jeszcze dwa lata temu 128 000 tokenów uchodziło za coś imponującego. Dziś 1 milion tokenów to nowy standard dla modeli z czołówki. Gemini 3.1 Pro idzie do 2 milionów. Llama 4 Scout osiąga 10 milionów.
Większe nie zawsze znaczy lepsze
Tu dochodzimy do części, którą większość artykułów pomija.
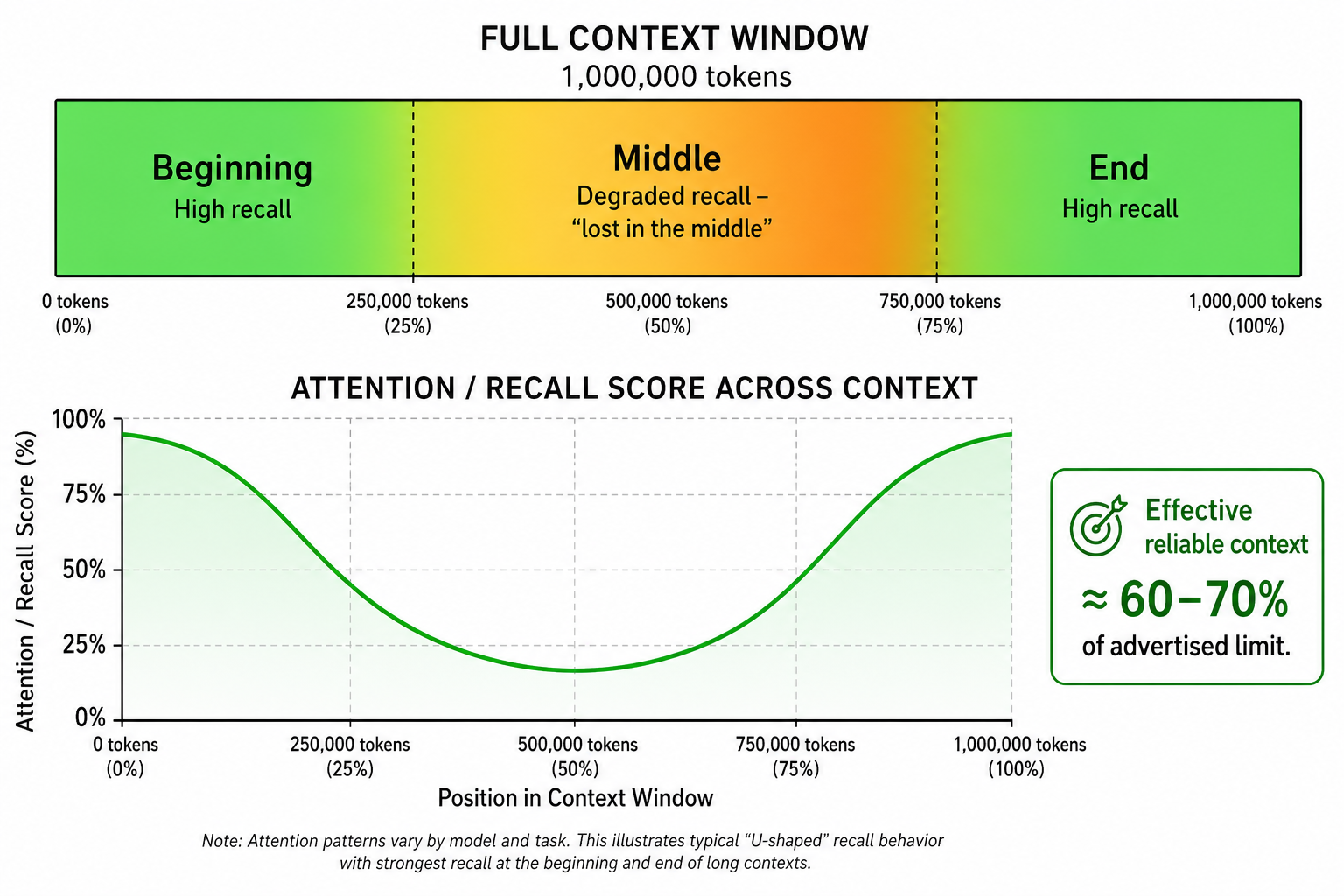
Duże context window nie oznacza, że model równie dobrze wykorzystuje je w całości. Badania z 2026 roku konsekwentnie pokazują, że modele AI zwykle poświęcają więcej uwagi informacjom z początku i końca context window — a rzeczy ukryte pośrodku potrafią po prostu „zgubić”.
Czasem nazywa się to context rot albo problemem „lost in the middle”. Nawet najbardziej zaawansowane modele z czołówki gorzej odtwarzają kluczowe informacje, jeśli są one zakopane głęboko w promptcie liczącym 1 milion tokenów.
Problem „lost in the middle”
Model reklamujący 1M tokenów nie jest tym samym co model, który niezawodnie rozumie i pamięta wszystko w całym zakresie tych 1M tokenów. W praktyce realnie użyteczny kontekst dla stabilnego działania często wynosi raczej 60–70% deklarowanego limitu. Dlatego to, jak strukturyzujesz kontekst, ma równie duże znaczenie jak to, ile go masz.
Różnica między context window a pamięcią
Ludzie często mylą context window z pamięcią. To nie jest to samo.
Context window jest aktywne i tymczasowe. To wszystko, co model widzi w tej chwili, w tej konkretnej rozmowie. Gdy rozmowa się kończy, ten kontekst znika.
Pamięć, w rozumieniu AI, to coś innego: system, który przechowuje informacje poza samą rozmową i odzyskuje je później. Niektóre produkty AI zaczynają już budować funkcje trwałej pamięci na swoich modelach. Ale podstawowy context window nadal pozostaje silnikiem — pamięć jest tylko sposobem na ponowne dostarczenie do niego przydatnych informacji.
Twój mózg robi obie te rzeczy jednocześnie, a Ty nawet tego nie zauważasz. AI nadal próbuje nadgonić.
Co to oznacza dla sposobu, w jaki korzystasz z AI
Kilka praktycznych wniosków:
Najważniejsze rzeczy podawaj od razu. Rozpoczynając rozmowę z AI, od początku dostarcz kontekst. Jaki jest Twój cel, kto jest odbiorcą, jakie masz ograniczenia, jakie preferencje. Nie zmuszaj modelu do zgadywania. Im więcej kontekstu podasz na starcie, tym lepsza będzie każda kolejna odpowiedź.
Długie rozmowy tracą na jakości. Im dłużej trwa czat, tym bardziej kontekst się zagęszcza i wypiera wcześniejsze informacje. Jeśli pracujesz nad czymś złożonym, warto rozważyć rozpoczynanie nowych sesji na różne etapy pracy zamiast ciągnięcia jednego nieskończonego wątku.
Wklejaj to, co istotne. Jeśli masz dokument, brief albo zestaw instrukcji, które są ważne — wklej je. AI nie czyta Ci w myślach. Kontekst, którego nie widzi, to kontekst, którego nie może użyć.
Większe context window naprawdę otwierają nowe zastosowania. Dzięki modelom 1M+ tokenów możesz dziś kazać AI przeczytać całą bibliotekę dokumentów firmowych przed odpowiedzią na pytanie. Albo przeanalizować pełną bazę kodu. Albo od razu podsumować wiele miesięcy opinii klientów. To nie są kosmetyczne usprawnienia — to jakościowo nowe możliwości.
Dlaczego Kunya powstała właśnie wokół tego
Większość platform AI daje Ci model. Kunya daje Ci właściwy model, z właściwym kontekstem, we właściwym momencie — i ta różnica zmienia wszystko.
Dajemy Ci dostęp do wszystkich modeli z czołówki wymienionych wyżej, w każdym przedziale context window, w jednym miejscu. Niezależnie od tego, czy potrzebujesz 2-milionowego context window Gemini 3.1 Pro do przetworzenia ogromnej biblioteki dokumentów, Claude Opus 4.8 do długofalowej pracy agentowej, czy GPT-5.5 do złożonego rozumowania z zachowaniem pełnego kontekstu — możesz przełączać się między nimi w tym samym interfejsie, bez żonglowania osobnymi subskrypcjami, osobnymi loginami i osobnymi rachunkami.
Ale dostęp do dużych context window to dopiero połowa problemu.
Druga połowa to wiedzieć, co właściwie należy w nich umieścić.
Wrzu cenie wszystkiego, co masz, do context window o rozmiarze 1 miliona tokenów nie jest strategią. To szum. Opisany wcześniej problem „lost in the middle” nie znika tylko dlatego, że masz więcej miejsca — wręcz się nasila, gdy kontekst jest przeładowany, nieprecyzyjny albo źle uporządkowany. Context window wypełnione nieistotnymi informacjami aktywnie szkodzi. Rozmywa sygnał. Popycha model w stronę niewłaściwych tropów.
Dlatego Kunya została zbudowana wokół inteligentnego zarządzania kontekstem, a nie wyłącznie wokół dostępu do dużych context window.
Agenci i narzędzia Kunya zostały zaprojektowane tak, by ustalić, co dokładnie powinno trafić do context window, zanim model w ogóle to zobaczy. Zamiast ładować wszystko i liczyć na najlepsze, narzędzia wyszukiwania Kunya pobierają konkretne dokumenty, fragmenty, historię rozmów albo punkty danych, które faktycznie są istotne dla Twojego bieżącego zadania. To trochę jak asystent badawczy, który przegląda całe archiwum za Ciebie — i podaje Ci tylko te trzy strony, które naprawdę mają znaczenie.
Inteligentne pobieranie kontekstu: zamiast ładować wszystko, narzędzia Kunya pokazują tylko to, co naprawdę istotne — dzięki czemu model pracuje na sygnale, a nie na szumie.
To daje dwie korzyści. Po pierwsze, radykalnie poprawia jakość odpowiedzi AI, bo dostarczony kontekst jest gęsty od sygnału, a nie rozwodniony przez szum. Po drugie, chroni Cię przed marnowaniem tokenów na treści, które i tak nigdy by nie pomogły. Context window są potężne, ale nie są darmowe. Każdy token ma znaczenie, zwłaszcza przy większej skali.
Nasze workflow agentowe idą o krok dalej. Agenci Kunya potrafią rozbijać złożone zadania na etapy, przekazując dalej na każdym z nich tylko istotny kontekst, zamiast ciągnąć przez cały proces ciężar wszystkich informacji naraz. Model zawsze ma to, czego potrzebuje. Nigdy nie niesie więcej, niż powinien.
Ta filozofia leży także u podstaw KunyaV1, naszego własnego, autorskiego dużego modelu językowego. KunyaV1 nie został zaprojektowany z myślą o surowej liczbie parametrów ani o pozycji w benchmarkowych rankingach. Został zaprojektowany wokół efektywności kontekstu — zdolności do wydobywania maksymalnego zrozumienia z dobrze ustrukturyzowanego, precyzyjnie ograniczonego context window. Podczas gdy wiele modeli jest trenowanych tak, by radziły sobie z czymkolwiek, co się do nich wrzuci, KunyaV1 jest trenowany do pracy z czystym, celowym kontekstem i do zwracania odpowiedzi, które tę precyzję oddają.
To inny zakład niż ten, który stawia większość branży. Ale naszym zdaniem to właśnie właściwy kierunek. Bo po wszystkim, co pokazują badania, i po wszystkim, co zbudowaliśmy oraz przetestowaliśmy, wciąż dochodzimy do tego samego wniosku: model, który mądrze wykorzystuje swój kontekst, będzie lepszy od modelu, który po prostu ma go więcej.
Kontekst jest wszystkim. Kunya została zbudowana na tym przekonaniu.
Wypróbuj Kunya za darmo
Poznaj ponad 100 modeli we wszystkich przedziałach context window — od 1M do 10M tokenów — na jednej platformie. Bez karty kredytowej.


